Tree Search Distillation for Language Models using PPO
03-01-2026 · Updated 03-03-2026
Game-playing neural networks like AlphaZero achieve superhuman performance in board games by augmenting the raw policy with a test-time search harness and distilling the stronger, augmented policy back into the network. Why aren’t similar techniques used in language modelling today? The DeepSeek-R1 authors mention they found limited success with MCTS; Finbarr Timbers has an excellent post on why they may have faced this problem, namely their choice of UCT instead of pUCT.
The purpose of this post is to explore two questions:
- Is it possible that search distillation actually improves language model reasoning?
- How does it perform relative to standard language RL methods, e.g. GRPO?
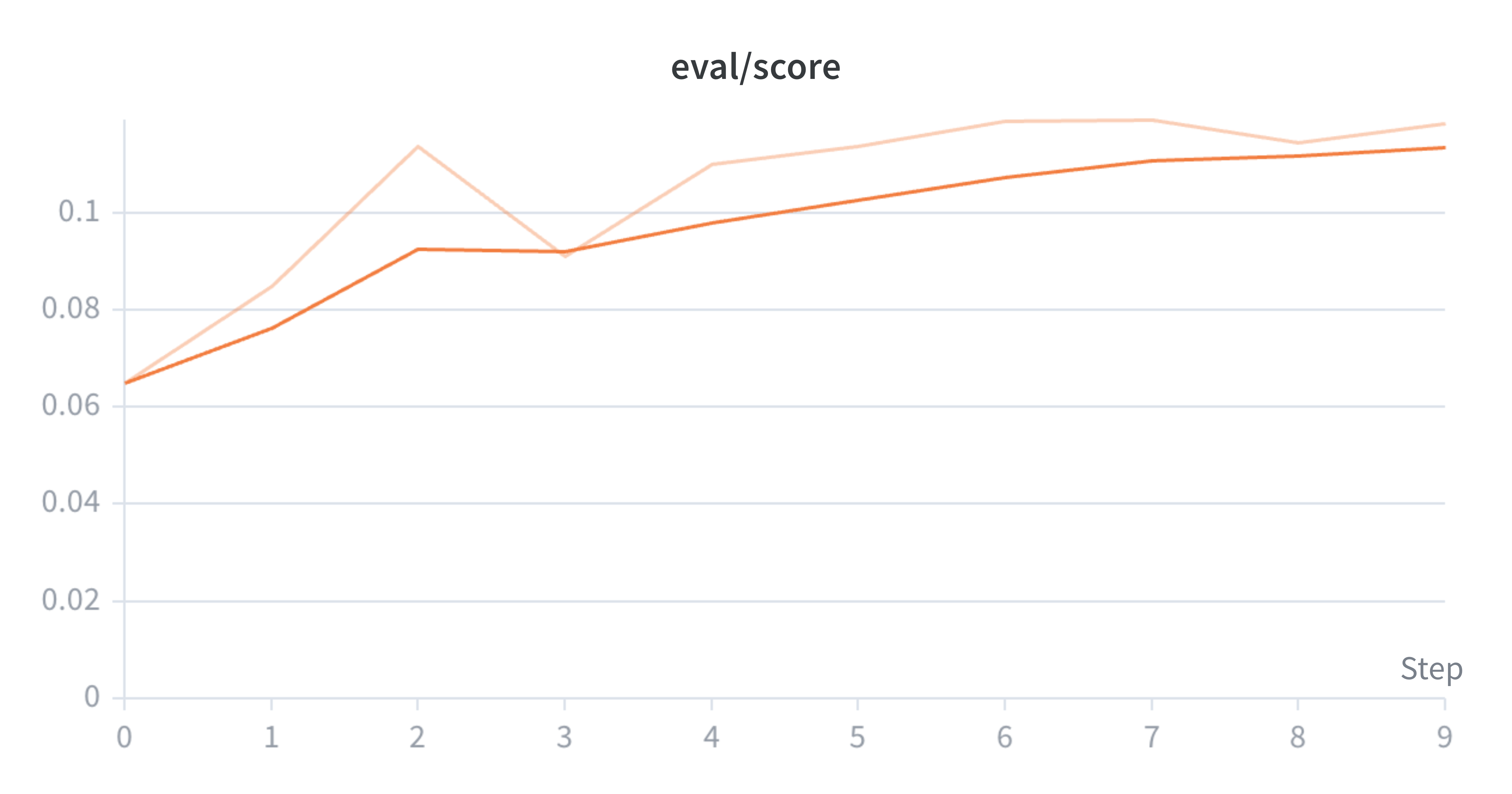
To explore this, I applied MCTS across reasoning steps to Qwen-2.5-1.5B-Instruct, to search for stronger trajectories and distill these back into the model via an online PPO loop. On the task of Countdown, a combinatorial arithmetic game, the distilled model (evaluated without a search harness) achieves an asymptotic mean@16 eval score of 11.3%, compared to 8.4% for CISPO and 7.7% for best-of-N. Relative to the pre-RL instruct model (3.1%), this is an 8.2 percentage point improvement.
The low absolute scores reflect the fact that these are small-scale experiments on a 1.5B model. I want to use this post as the first in a series, and hope to see these scores increase in subsequent blog posts as I use larger models and compute budgets.
Countdown
I initially tried using GSM8K as the environment to test this method, but found minimal differences between GRPO and MCTS to make a strong claim either way. Instead, I decided to go with the game of Countdown as our environment. The premise is simple: given a set of N positive integers, use standard operations (+, -, /, *) to compute a particular target. Why Countdown? The hypothesis is that combinatorial problems benefit more from the sort of parallel adaptive reasoning tree search enables, as opposed to, say, GSM8K where sequential reasoning also leads to effective outcomes. We train on a dataset of 20,000 samples, and evaluate on a test set of 820 samples. Each sample consists of four input integers, between 1 and 13.
I found that using a sparse reward (0/1 for correctness) during training results in unstable training. Switching to a dense reward function:
$1.0 - 2 \cdot \min\left(\frac{|t - p|}{t}, 1.0\right)$ if formatting is correct, else $-1.0$
Here, $t$ is the true target and $p$ is the predicted target.
However, evaluation still uses the sparse reward function, since we’d like to be able to intuit the scores (e.g. % pass rate).
Monte Carlo Tree Search
The MCTS algorithm has been covered in-depth by others, so I’m going to skip a detailed description: for the purposes of this post I’d like to focus on the delta between classical MCTS and the method I tried. Briefly speaking, MCTS iteratively builds a search tree to intelligently explore the action space, guided by a value function.
Board games have a relatively meaningful action space, i.e. each move in chess tends to have a substantial effect on whether the player wins or not. Contrast that to language modelling, where many tokens in a reasoning trace act as fillers or syntactic sugar, and branching from the top-k logits (or conditioning on an entropy threshold) doesn’t always result in search diversity. Imagine a state where the next probable tokens are “but”, “however”, “yet” etc; we would end up spending computational resources to build prohibitively large search trees with marginal benefit on a per-token basis.
I prefer the approach introduced by Tree-of-Thoughts (Yao et al., 2023) to search over possible next reasoning steps. In this formulation each node-state is a sequence of contiguous tokens:
- The root node corresponds to the input prompt
- Intermediate nodes correspond to reasoning steps:
<step>...</step> - Terminal nodes correspond to answers:
<answer>...</answer>
In the spirit of investigating more scaling “knobs”, my implementation uses parallel MCTS, where N agents share the same per-sample search tree and use virtual losses to encourage search diversity.
Starting from each leaf node, we produce K completions until the stop tag </step> is encountered. These K sequences form our action space for that particular node.
Since pUCT requires action-level priors, we compute sequence-level summed logprobs and apply the softmax function to get relative priors. These play nice since raw cumulative sequence probabilities become vanishingly tiny and numerically unstable.
MCTS also generally uses a value head $V(s_t)$ that improves over training and helps guide the search process to better trajectories. This is implemented as an MLP followed by a tanh function applied to the final hidden state of the transformer.
This approach shares similarities with TS-LLM (Feng et al., 2023), which also combines AlphaZero-style tree search with a learned value function over sentence-level actions.
The key differences are:
- Using online RL (CISPO/PPO) rather than SFT for distillation
- Parallel MCTS with virtual losses as an additional scaling axis
Trajectory Selection
Normally with board game MCTS, the training signal comes from minimising KL divergence between the search policy at the root node and the raw policy the model predicts. However, since there is a mismatch in the granularity of our action space relative to the raw model action space (reasoning steps vs. tokens), we need to do something else. The approach I use is that after all workers complete M iterations of the algorithm for a particular sample, they perform a greedy selection process:
- Starting from the root, select a trajectory by maximum visit count
- Submit this trajectory to a shared buffer to be used for PPO training
Training
Workers designated as “trainers” asynchronously pull samples from the shared buffer. They use the AdamW optimiser and perform a single PPO inner step for each batch of B samples, with CISPO as our loss type.
The training objective is to minimise the total loss $L_{total}$:
$L_{total} = c_{ppo} L_{ppo} + c_{value} L_{value} + c_{KL}\, \mathbb{D}_{KL}(\pi_\theta \mid\mid \pi_{ref})$
$L_{cispo} = -\mathbb{E}\left[sg(\min(\frac{\pi_\theta(a_t \mid s_t)}{\pi_{old}(a_t \mid s_t)}), \epsilon) \cdot A_t \cdot \log \pi_\theta(a_t \mid s_t) \right]$
where $A_t = r_{terminal} - sg\!\left(V_{old}(s_t)\right)$ is a token level advantage (we assign the same terminal reward to each token). I didn’t use GAE because reasoning traces can extend to thousands of tokens, and with a terminal reward, early tokens get exponentially discounted to negligibly small values.
$L_{value} = \mathbb{E} \left[(V(s_t) - r)^2\right]$
$\mathbb{D}_{KL}(\pi_\theta \mid\mid \pi_{ref}) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{ref}(a_t \mid s_t)} - \log \frac{\pi_\theta(a_t \mid s_t)}{\pi _{ref}(a_t \mid s_t)} - 1$ (from the DeepSeek-R1 paper)
We run the training process until the eval score plateaus.
Infrastructure
All experiments were performed on a 8xH100 node from Andromeda. For MCTS, six of the GPUs are designated as generators, while two are trainers. A Rust worker samples questions from the dataset and submits inference requests to a generator pool exposed via gRPC. They write the selected trajectories to a Redis stream; trainers iteratively pull samples from here. Weights are synced between generators and trainers every 8 gradient steps using Redis pub/sub.
Baselines
I ran a CISPO baseline with a global batch size of 128 samples and a group size of 16, resulting in an effective batch size of 2048. Logits were computed in float32 as per ScaleRL. Again, training ran until the eval score plateaued. All eight GPUs were used to train CISPO and there was no trainer/generator split.
To isolate the value-add of the tree structure, I ran experiments where the trajectories submitted to our training buffer were selected via “best-of-N” (N=64) instead of tree search.
Results
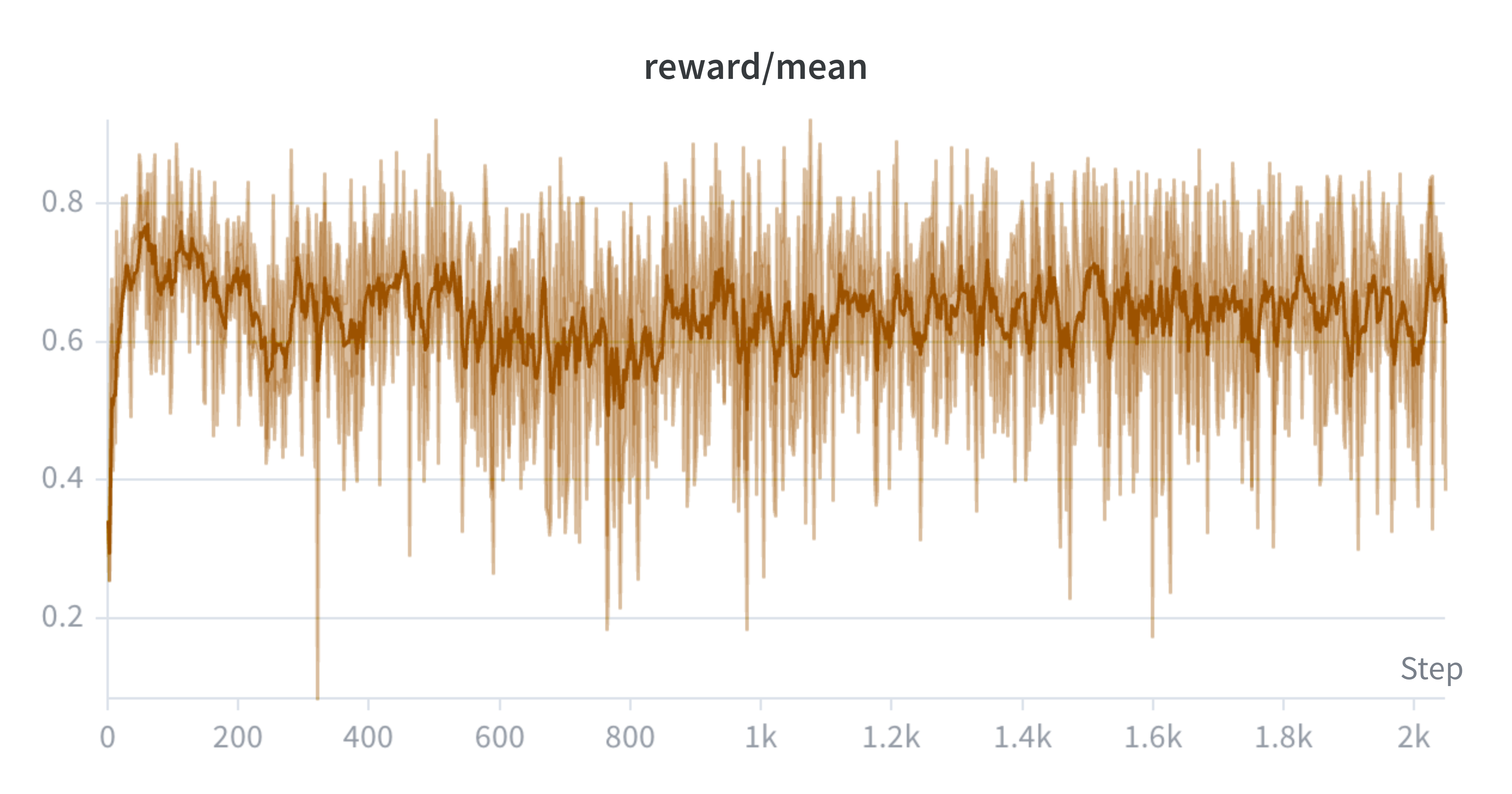
We use mean@16 to evaluate the model. This means running 16 generations for each eval prompt, grading them with a sparse 0/1 reward, and averaging the results. During evaluation the MCTS-distilled policy with no search harness achieves an asymptotic mean@16 score of 11.3%, while the CISPO model asymptotes at 8.4%, and Best-of-N performs the worst, plateauing at 7.7%.
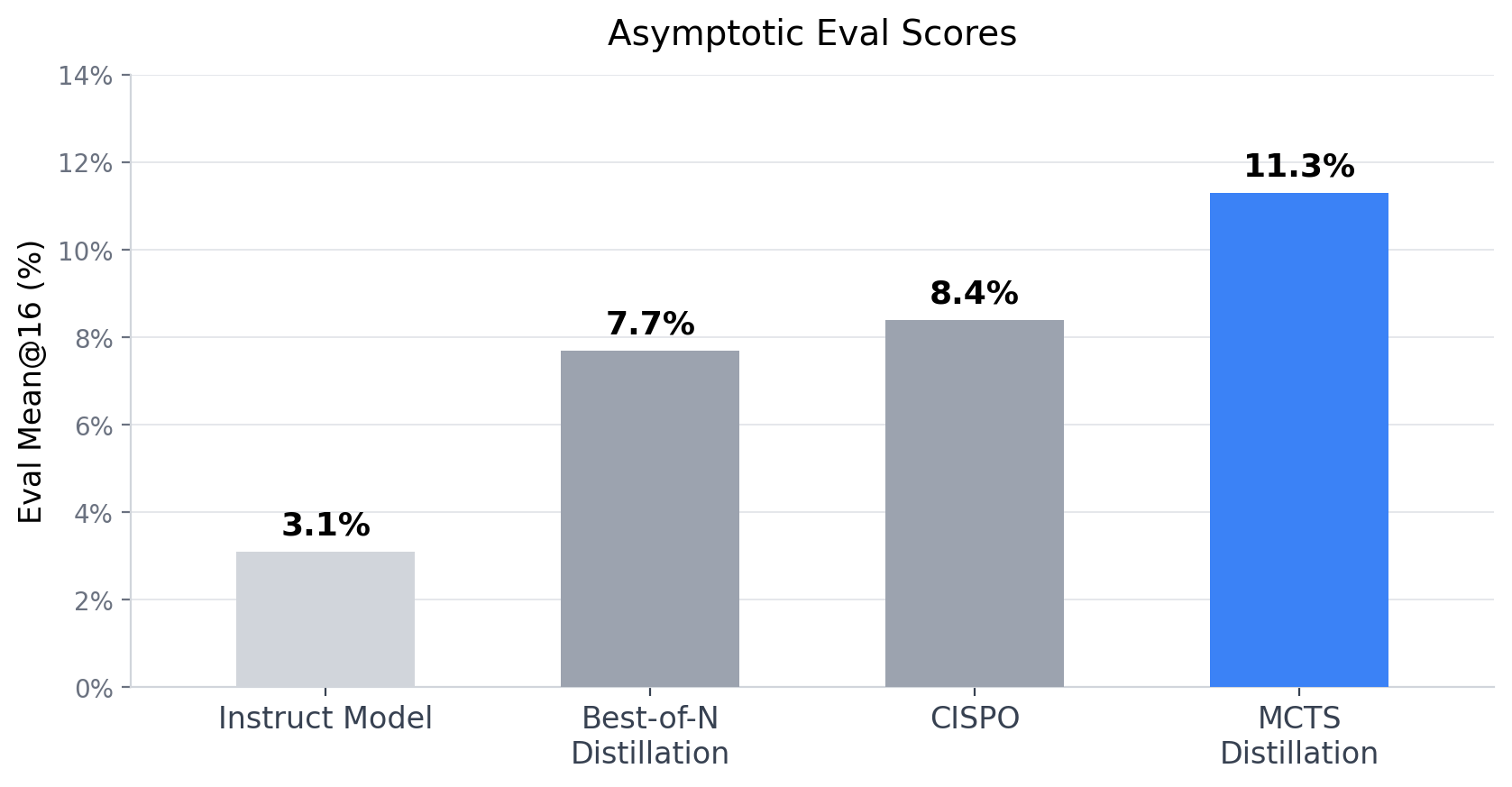
Surprisingly, I also found that despite the training reward being significantly higher, “best-of-N” distillation underperforms both CISPO and MCTS on the eval suite. While it’s not entirely clear why, we can theorise: if our model has a 98% chance of making at least one reasoning error during its thinking trace, there’s still a $1 - 0.98^{64} \approx 72.6 \%$ chance of selecting at least one correct trajectory. But if there’s no incentive to produce robust reasoning every time, it’s unlikely the model will learn to develop strategies that improve its single-shot score. In secondary school I used a number of techniques to keep track of intermediate steps when solving maths problems. This significantly reduced the probability of making “dumb mistakes” in exams. If I had the option to take the exam multiple times I would never have adopted those techniques!
Code
All code is open source and can be found here.
Future Directions
So what does this mean? The part that excites me here is the additional reasoning knobs we can tune, like the number of parallel workers per tree, or the number of MCTS iterations. I haven't tuned these properly, but initial experiments showed increasing both these values led to significant performance gains. So I want to explore this direction further! There's plenty of work to be done scaling this method and charting empirical trends to evaluate its potential for larger models and compute budgets. Reach out if you would like to collaborate!
Now for the caveats: it’s possible this is a “small model phenomenon”, and the method doesn’t scale as well as GRPO for larger models etc. Is it possible to tune the GRPO (CISPO) baseline to match MCTS? Perhaps, but ScaleRL found that most hyperparameters for GRPO adjust compute efficiency, not the final reward ceiling.
One might note that MCTS uses more inference compute on a per-sample basis than GRPO: of course it performs better! However, the goal here is not to make an apples-to-apples compute comparison; yes, MCTS does use more inference-time compute, but it also gives us additional levers for applying/scaling that compute and raising the reward ceiling. Whereas it's not obvious to me that throwing 100x more compute at GRPO would have turned the plateau into a hockey stick.
Acknowledgements
I’d like to thank the Andromeda team and Molly Mielke McCarthy for sponsoring compute for this project, as well as Tom McCarthy and Joe Melkonian for reading over early drafts of this post and offering valuable feedback. I’d also like to thank Finbarr Timbers for the blog post that acted as the impetus for this work.
Table of Values
| Parameter | Value | Description |
|---|---|---|
| Base Model | Qwen-2.5-1.5B-Instruct | Foundation model used for experiments |
| Training Dataset Size | 20,000 samples | Number of Countdown problems for training |
| Evaluation Set Size | 820 samples | Number of problems in eval set |
| N (integers per problem) | 4 | Number of integers in each Countdown problem |
| Input Bounds | [1, 13] | Range for input integers |
| MCTS Workers (N agents) | 16 | Number of parallel agents sharing one search tree |
| Completions per Node (K) | 4 | Number of candidate sequences generated at each leaf |
| MCTS Iterations (M) | 100 | Number of iterations per sample |
| Virtual Loss | 1 | Value added to visit counts to discourage parallel branch collisions |
| MCTS/BoN Global Batch Size | 32 | Total batch size for MCTS/Best-of-N training |
| CISPO Global Batch Size | 128 | Total batch size for baseline training |
| CISPO Group Size | 16 | Number of trajectories per group |
| CISPO epsilon_high | 5.0 | Clipping parameter for CISPO |
| Best-of-N Sample Size | 64 | N, or the number of generations per sample for best-of-N baseline |
| Weight Sync Frequency | Every 8 gradient steps | How often weights sync between generators and trainers |
| cpuct | 0.5 | pUCT coefficient |
| cKL | 0.05 | KL divergence weight |
| cppo | 1.0 | PPO objective weight |
| cvalue | 1.0 | Value objective weight |
| Nt | 2 | Number of trainer processes |
| Ng | 6 | Number of generator processes |
Appendix: Experimental Curves
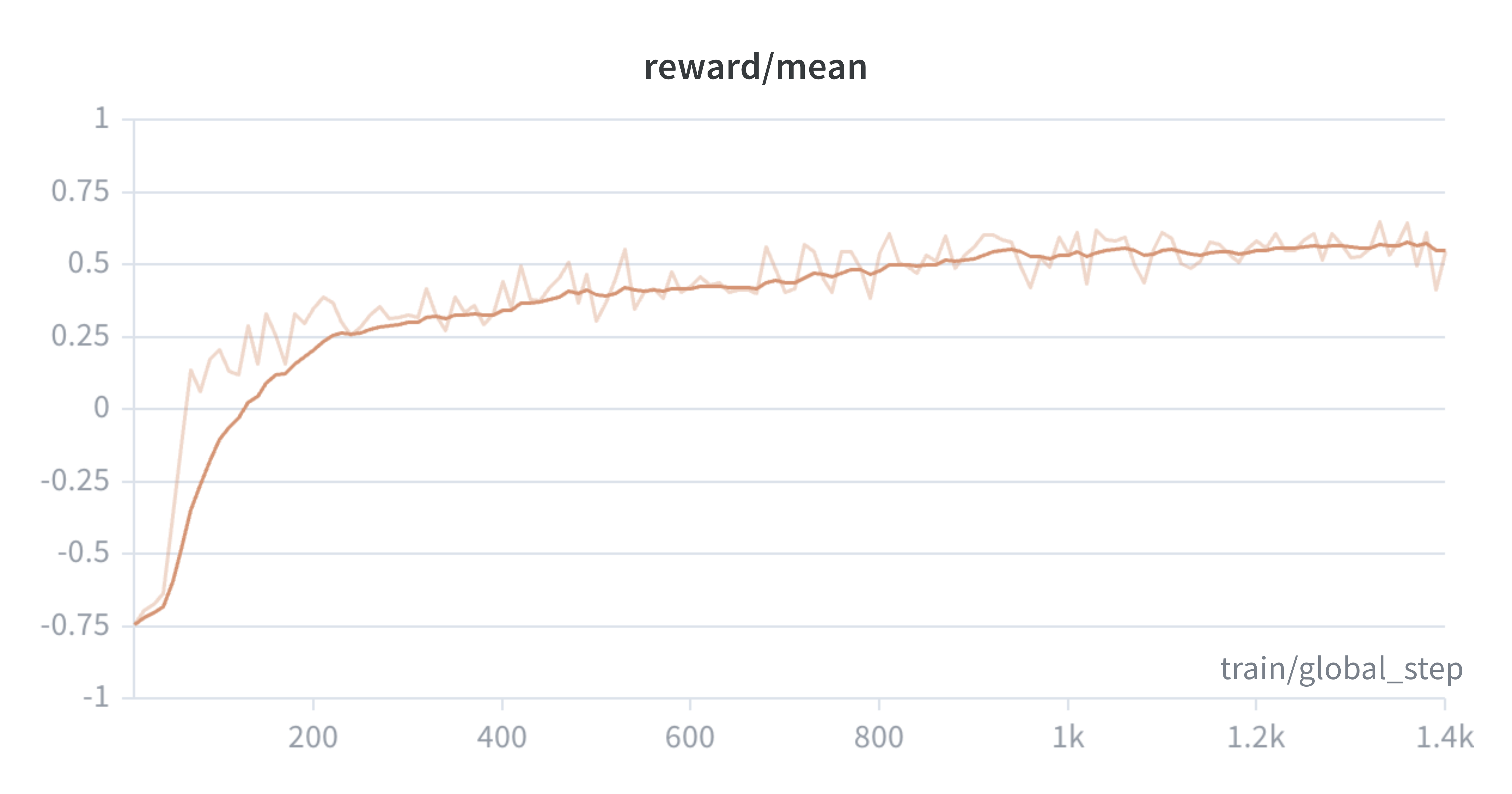
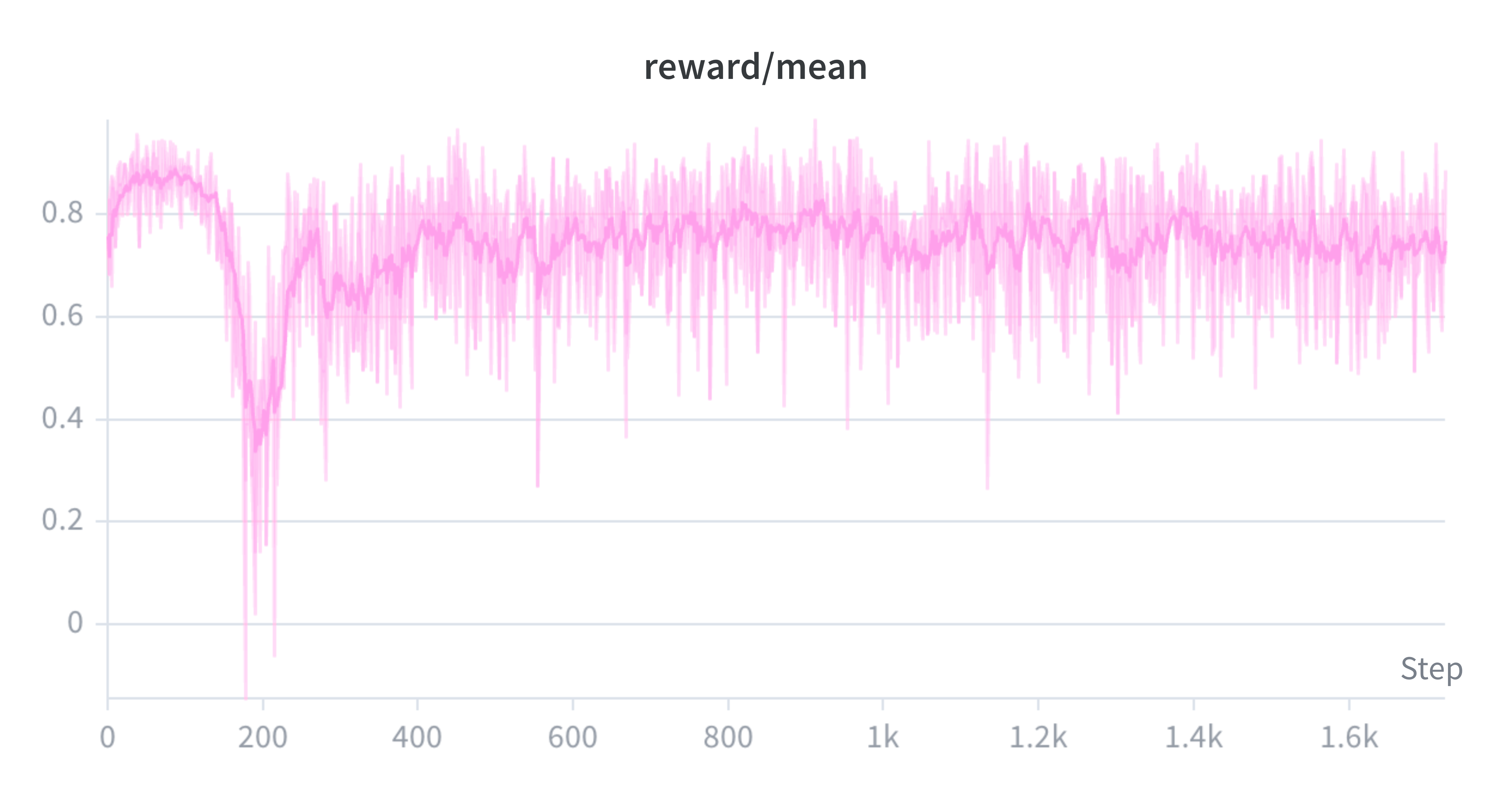
Note that we use a different logging cadence for each run, which is partially why the x-axis limits differ. We train the models until the eval score plateaus.
Evaluation
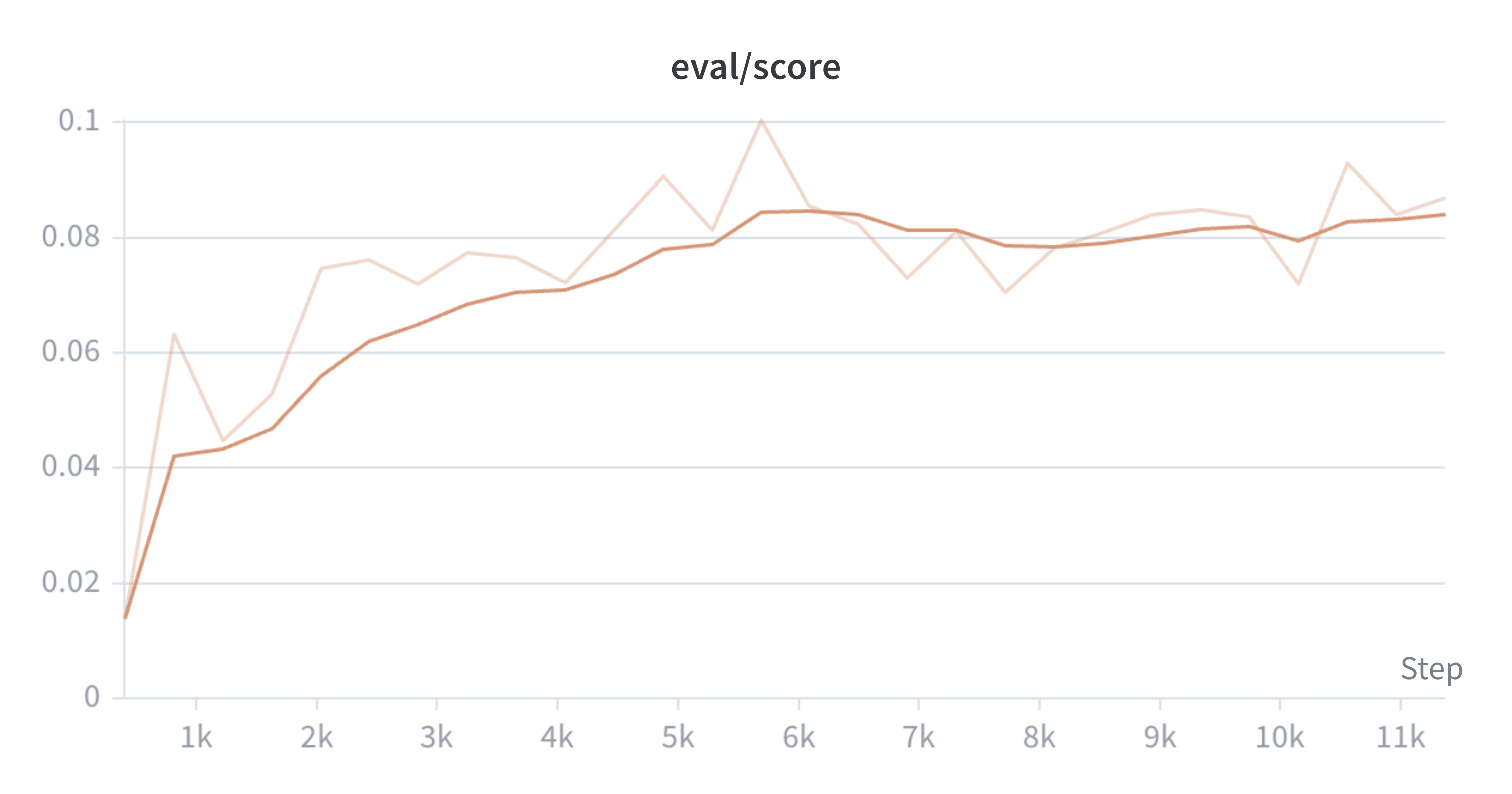
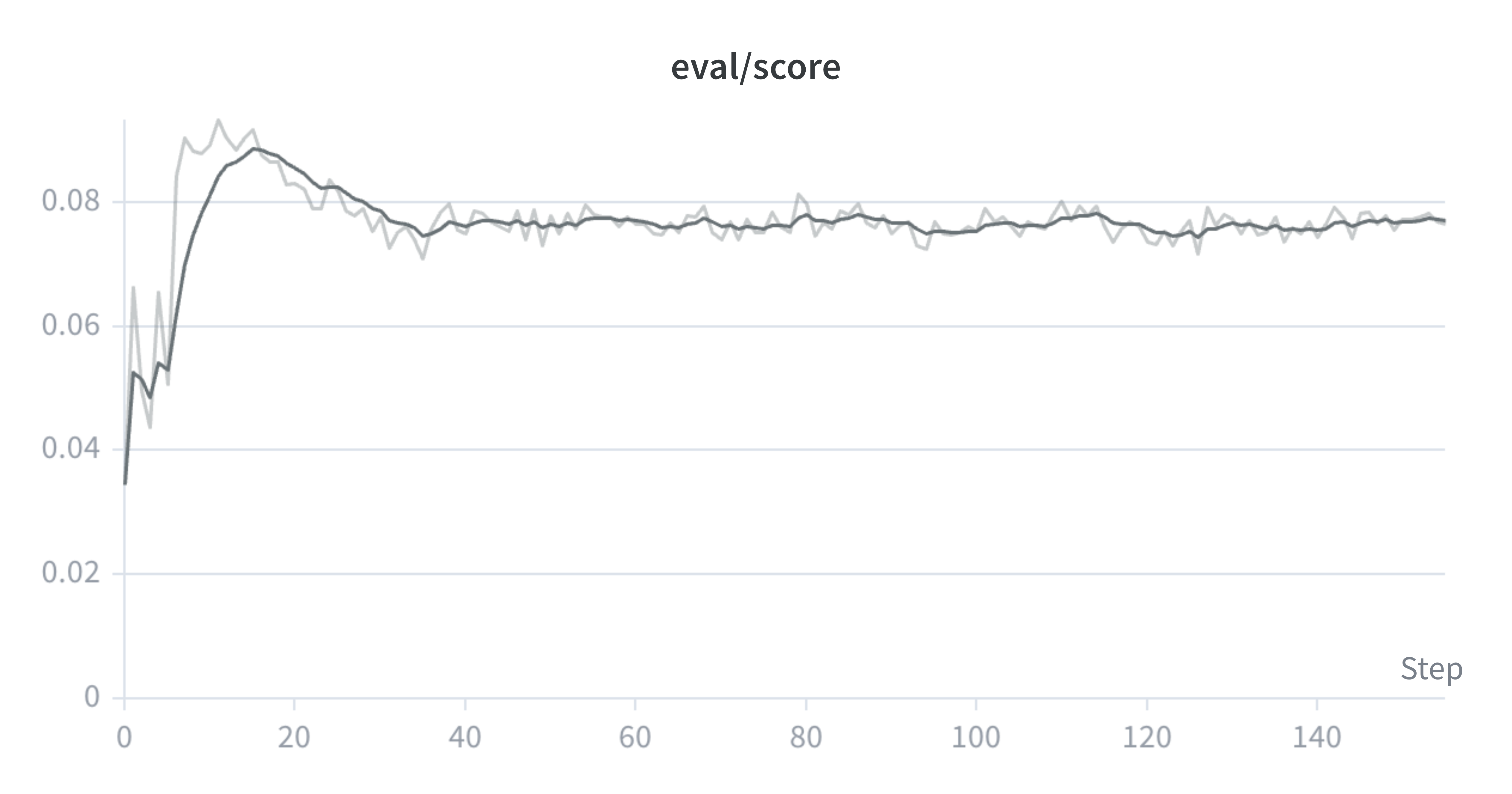
Training